
Nel precedente articolo abbiamo visto una introduzione generale ad OpenSearch (clicca qui per leggerlo). Ora iniziamo a capire come è fatto, quali sono i componenti che lo compongono, come comunicano tra loro e perché questa architettura è così efficace nel gestire grandi quantità di dati.
Immaginiamo di dover gestire i log di accesso di un grande sito web. Ogni visitatore genera decine di eventi: pagine viste, click, ricerche, errori. Con un milione di visitatori al giorno, ci si ritrova facilmente con decine di milioni di righe di dati ogni 24 ore. Nel corso di un anno, stiamo parlando di miliardi di record.
Come si cercano? Come si analizzano? Come si visualizzano in tempo reale?
Un database relazionale tradizionale, come MySQL o PostgreSQL, faticherebbe enormemente con questi volumi e non è progettato per questo tipo di carico: le ricerche full-text sono lente, la scalabilità è limitata e le query di analisi su miliardi di righe richiedono risorse enormi.
OpenSearch nasce per risolvere esattamente questo problema e la sua architettura è la risposta a questa sfida.
Documento
In OpenSearch, l’unità base di dati si chiama Documento. Un documento è semplicemente un oggetto in formato JSON che potrebbe rappresentare un evento di log come nel seguente esempio
{
"timestamp": "2025-03-15T14:23:01Z",
"livello": "ERROR",
"servizio": "api-gateway",
"messaggio": "Connessione al database fallita",
"ip_sorgente": "192.168.1.45",
"durata_ms": 5023
}Ogni documento ha un identificatore univoco (un ID), può contenere qualsiasi campo si voglia e viene memorizzato e ricercato come unità atomica.
Indice
I documenti non vengono salvati in modo casuale ma vengono organizzati in indici. Un indice è un contenitore logico per un insieme di documenti correlati, simile a una tabella in un database relazionale, ma molto più flessibile. Ad esempio, si potrebbe avere:
- Un indice log-nginx-2025-03 per i log del web server di marzo
- Un indice log-nginx-2025-04 per quelli di aprile
- Un indice eventi-sicurezza per gli alert del firewall
- Un indice prodotti per il catalogo del sito di e-commerce
Ogni indice ha un nome, una configurazione e un mapping (la struttura dei campi) e quando si cerca un dato è possibile farlo all’interno di un singolo indice o su più indici contemporaneamente.
Shard
Passiamo ora al concetto più importante dell’architettura di OpenSearch, quello che rende tutto possibile: lo shard.
Pensa a un indice come a un grande libro. Se il libro ha un milione di pagine, è impossibile leggerlo tutto in poco tempo. Ma se lo dividiamo in 10 volumi da 100.000 pagine ciascuno, e si da ogni volume a un lettore diverso, è possibile leggerlo in parallelo, 10 volte più velocemente.
Uno shard è esattamente questo, una porzione di un indice. Quando si crea un indice in OpenSearch possiamo configurarlo per essere diviso in più shard, ad esempio 3, 5 o 10. Ogni shard è un’istanza indipendente del motore di ricerca Apache Lucene e può vivere su una macchina diversa garantendo due vantaggi enormi
- Scalabilità orizzontale: se i dati crescono, possiamo aggiungere più macchine e distribuire gli shard su di esse. Non è necessario prevedere un server sempre più potente (scalabilità verticale, costosa e con limiti fisici), ma si aggiungono semplicemente altri server (scalabilità orizzontale, economica e praticamente illimitata)
- Parallelismo: quando si esegue una query, OpenSearch la manda a tutti gli shard in parallelo, raccoglie i risultati parziali e li combina. Con 5 shard, la ricerca è potenzialmente 5 volte più veloce che su un indice non diviso
Gli shard descritti finora si chiamano shard primari ma OpenSearch introduce un secondo tipo di shard, le repliche. Una replica è una copia esatta di uno shard primario che vive su una macchina diversa e serve a due scopi
- Alta disponibilità: se la macchina che ospita uno shard primario si guasta, OpenSearch promuove automaticamente la sua replica a shard primario garantendo che il cluster continua a funzionare senza interruzioni e senza perdita di dati
- Maggiore throughput in lettura: le ricerche possono essere eseguite sia sugli shard primari che sulle repliche, distribuendo il carico e aumentando le performance complessive
Cluster OpenSearch
Un cluster OpenSearch è un insieme di una o più macchine, chiamate nodi, che lavorano insieme come un sistema unico. Dal punto di vista esterno, un cluster appare come una sola entità: si invia una query al cluster, e il cluster restituisce il risultato indipendentemente da quanti nodi lo compongono e da come i dati sono distribuiti al loro interno.
Ogni cluster ha un nome univoco (configurabile, il default è opensearch) e i nodi si trovano tra loro tramite un protocollo di scoperta automatica. Quando si avvia un nuovo nodo con il nome cluster corretto, questo si unisce automaticamente al cluster.
Non tutti i nodi in un cluster fanno la stessa cosa, OpenSearch definisce diversi ruoli che un nodo può svolgere. In un cluster piccolo un singolo nodo svolge tutti i ruoli contemporaneamente, mentre in un cluster di produzione di grandi dimensioni i ruoli vengono separati su nodi dedicati per ottimizzare le performance.
Il nodo master (o Cluster Manager) è il “cervello” del cluster ed è responsabile di tutte le operazioni di gestione
- Tenere traccia di quali nodi fanno parte del cluster
- Decidere dove posizionare gli shard quando viene creato un nuovo indice
- Rilevare i nodi che hanno un malfunzionamento e riorganizzare gli shard di conseguenza
- Gestire le modifiche alla configurazione del cluster
In un cluster in produzione si usano almeno 3 nodi master (o nodi master-eligible) per garantire l’alta disponibilità.
I nodi data ospitano gli shard con i dati effettivi e si occupano di
- Archiviare i documenti
- Eseguire le query di ricerca sugli shard locali
- Indicizzare i nuovi documenti in arrivo
In un cluster di produzione, i nodi data sono tipicamente le macchine più numerose e con più storage e RAM.
I nodi ingest si occupano di trasformare i dati. Prima che un documento venga salvato, può passare attraverso una pipeline di ingest, ovvero una serie di operazioni che modificano, arricchiscono o filtrano il documento. Ad esempio
- Estrarre l’indirizzo IP da una stringa di log
- Aggiungere informazioni geografiche a partire dall’IP
- Convertire un timestamp da un formato a un altro
- Rimuovere campi sensibili prima dell’archiviazione
Il nodo coordinating non ospita dati, ma riceve le query dall’esterno e le distribuisce ai nodi data appropriati raccogliendo i risultati parziali e ricomponendoli in una risposta finale. In pratica qualsiasi nodo può svolgere il ruolo di coordinating per le query che riceve, anche se nei cluster grandi si dedicano nodi specifici a questo ruolo.
Come funziona una query
Ora che abbiamo visto i vari componenti analizziamo il flusso di una query in OpenSearch. Capirlo aiuta enormemente in fase di troubleshooting e per ottimizzare le performance.
Fase 1, Ricezione: si invia una query HTTP al cluster (ad esempio, “trovami tutti i log con livello ERROR delle ultime 24 ore”). La query arriva a un nodo, che assume il ruolo di coordinating per questa richiesta
Fase 2, Scatter (distribuzione): il nodo coordinating identifica quali shard, primari o repliche, contengono dati potenzialmente rilevanti e invia la query a ciascuno di essi in parallelo
Fase 3, Esecuzione locale: ogni shard esegue la query sui propri dati locali e restituisce al nodo coordinating un insieme di risultati parziali, tipicamente solo gli ID dei documenti rilevanti e i loro punteggi di rilevanza
Fase 4, Gather (raccolta): il nodo coordinating raccoglie tutti i risultati parziali, li ordina per rilevanza e determina quali documenti devono essere inclusi nella risposta finale
Fase 5, Fetch: il nodo coordinating recupera i documenti completi dagli shard che li ospitano
Fase 6, Risposta: il nodo coordinating restituisce la risposta finale al client, con i documenti ordinati per rilevanza
Tutto questo avviene tipicamente in millisecondi, anche con cluster di decine di nodi e indici con miliardi di documenti.
Come funziona l’indicizzazione
Anche l’inserimento di un documento segue un percorso preciso.
Fase 1, Ricezione: si invia un documento al cluster tramite API. Il nodo che riceve la richiesta diventa il coordinating node per questa operazione
Fase 2, Routing: il nodo calcola in quale shard primario deve andare il documento. Questo calcolo è deterministico, usando una formula matematica basata sull’ID del documento, in modo che lo stesso documento vada sempre nello stesso shard
Fase 3, Scrittura primaria: il documento viene scritto nello shard primario, che lo indicizza tramite Apache Lucene
Fase 4, Replica: lo shard primario invia il documento a tutte le sue repliche, che lo indicizzano a loro volta
Fase 5, Conferma: solo quando tutte le repliche hanno confermato la scrittura, il cluster risponde al client con un messaggio di successo. Questo garantisce che il dato non venga mai perso
Un esempio di cluster a 3 nodi
Per rendere tutto più concreto, immaginiamo un cluster con 3 nodi e un indice con 3 shard primari e 1 replica per shard
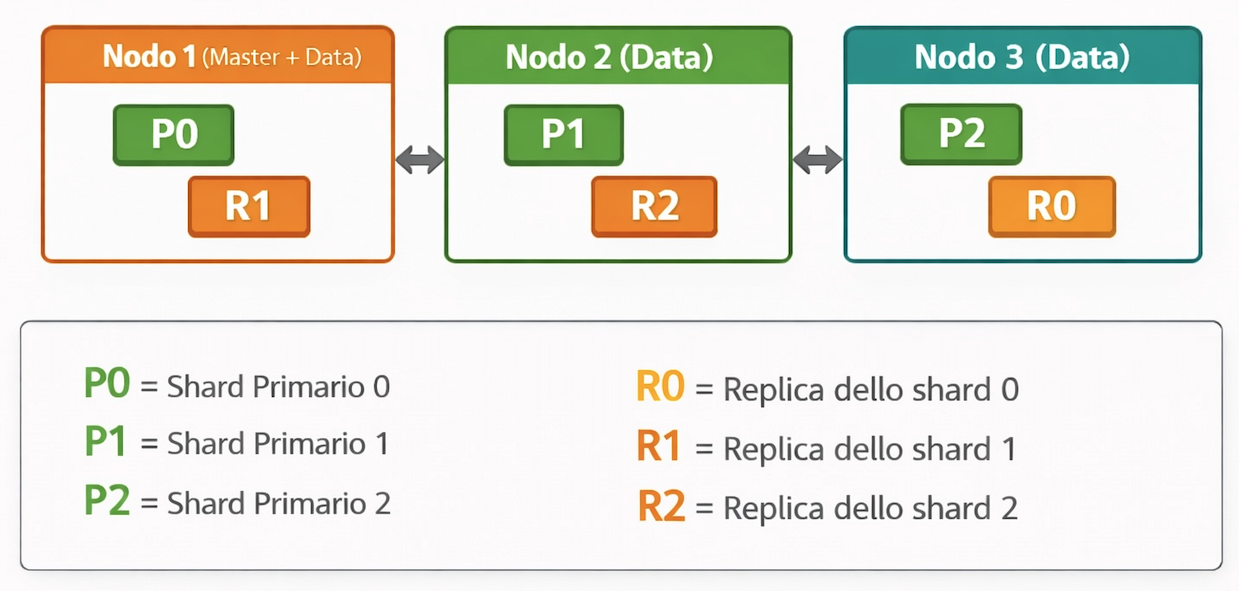
In questa configurazione, ogni nodo ospita uno shard primario e una replica, ma mai la replica del proprio shard primario. Se il Nodo 1 si guasta, il cluster ha ancora accesso a tutti i dati tramite
- le repliche sui Nodi 2 e 3
- R0 sul Nodo 3 viene promosso automaticamente a shard primario
Il ruolo di Apache Lucene
Vale la pena menzionare il motore che sta sotto tutto: Apache Lucene. OpenSearch (come Elasticsearch) non ha inventato il motore di ricerca da zero: utilizza Lucene, una libreria Java open source per la ricerca full-text, sviluppata dalla Apache Software Foundation.
Lucene è il vero responsabile dell’indicizzazione dei documenti e dell’esecuzione delle query ed è uno dei software più sofisticati e ottimizzati che esistano per la ricerca testuale. OpenSearch costruisce sopra Lucene uno strato di distribuzione, gestione del cluster, API REST e tutte le funzionalità aggiuntive che lo rendono facile da usare e scalabile.
Punti chiave visti in questo articolo
- I documenti sono le unità base di dati, in formato JSON
- Gli indici raggruppano documenti correlati
- Gli shard dividono gli indici per scalabilità e parallelismo
- Le repliche garantiscono affidabilità e performance in lettura
- I nodi ospitano shard e svolgono ruoli specifici
- Il cluster coordina tutto il sistema come un’unica entità
L’elenco degli articoli di questa serie può essere consultato qui

