
Tra gli errori HTTP che un amministratore di sistema si trova ad affrontare, il 502 Bad Gateway è uno dei più frequenti e, al tempo stesso, uno dei più insidiosi: la pagina smette di rispondere senza che Nginx mostri alcuna indicazione visibile sulla causa reale del problema.
Il codice HTTP 502 indica che il server, agendo da gateway o reverse proxy, ha ricevuto una risposta non valida, o nessuna risposta, dal server upstream a cui ha inoltrato la richiesta. In un tipico stack LEMP (Linux, Nginx, MySQL, PHP), Nginx non esegue direttamente il codice PHP: riceve la richiesta dal browser, la inoltra a PHP-FPM (FastCGI Process Manager) e restituisce al client la risposta elaborata. Quando questo canale di comunicazione si interrompe, Nginx restituire un errore 502.
Possiamo schematizzare il flusso in questo modo
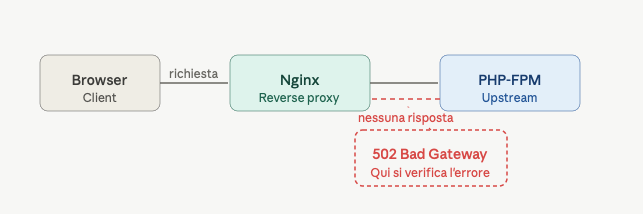
Leggere i log di Nginx
Il punto di partenza è sempre la lettura dei log. nginx mette a disposizione due file distinti che vanno usati in combinazione, access.log che ci da indicazioni del quando e dove si è verificato l’errore e error.log che di da indicazioni sulla causa.
Il codice 502 appare nel log degli accessi, che registra tutte le richieste HTTP con il relativo codice di risposta
grep " 502 " /var/log/nginx/access.log | tail -20
# Esempio di una riga di log
192.168.1.10 - - [25/Apr/2026:10:32:11 +0200] "GET /index.php HTTP/1.1" 502 166 "-" "Mozilla/5.0..."Questo log risponde alle domande quando si sono verificati i 502 e su quali URL, permettendo di correlare gli errori a orari o operazioni specifiche.
Il log degli errori non riporta il codice 502 direttamente, ma contiene la descrizione tecnica della causa. Per visualizzarlo in tempo reale possiamo usare il comando
tail -f /var/log/nginx/error.logmentre per filtrare i messaggi rilevanti, è preferibile usare una ricerca estesa che copra i pattern associabili ad un errore 502
grep -E "upstream|connect\(\)|Permission denied|no live" /var/log/nginx/error.log | tail -30Il flag -E abilita le espressioni regolari e permette di cercare più pattern contemporaneamente separati dal carattere |, catturando una gamma più ampia di errori in un unico comando.
Incrociando i timestamp dei due log si riesce a ricostruire esattamente cosa è successo e in quale momento
# 1. Verifico QUANDO e su quali URL si sono verificati i 502
grep " 502 " /var/log/nginx/access.log | tail -20
# 2. Verifico il MOTIVO tecnico
grep -E "upstream|connect\(\)|Permission denied|no live" /var/log/nginx/error.log | tail -30Ora vediamo le possibili cause per cui si potrebbe verificare questo errore.
PHP-FPM non è in esecuzione
È la causa più comune, se PHP-FPM è fermo per un problema, un riavvio del sistema o un aggiornamento andato male, nginx non riesce a inoltrargli le richieste e restituisce un errore 502.
# Messaggio nel log
connect() to unix:/run/php/php8.2-fpm.sock failed (111: Connection refused)
# Comando per la verifica dello stato del servizio
systemctl status php8.2-fpm
# Se è fermo, avviamo il servizio
systemctl start php8.2-fpm
systemctl enable php8.2-fpm # per abilitare l'avvio automaticoPer individuare il motivo di un problema nel funzionamento possiamo analizzare il log
journalctl -u php8.2-fpm --since "1 hour ago"Socket o porta errati nella configurazione Nginx
Nginx cerca PHP-FPM all’indirizzo specificato nella direttiva fastcgi_pass. Se il path del socket o la porta non corrispondono a quelli effettivamente in uso da PHP-FPM, la connessione fallisce.
# Messaggio nel log
connect() to unix:/run/php/php8.2-fpm.sock failed (2: No such file or directory)
# Controllare il socket effettivo usato da PHP-FPM
grep "^listen" /etc/php/8.2/fpm/pool.d/www.conf
# Esempio di output
listen = /run/php/php8.2-fpm.sockDobbiamo ora verificare nella configurazione di nginx
grep "fastcgi_pass" /etc/nginx/sites-enabled/il-tuo-sitoche i due valori corrispondano esattamente. Se non coincidono, va aggiornata la configurazione nginx di conseguenza
location ~ \.php$ {
fastcgi_pass unix:/run/php/php8.2-fpm.sock; # ← deve corrispondere a listen in www.conf
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}Dopo l’eventuale modifica del file di configurazione di nginx, testare e ricaricare
nginx -t && systemctl reload nginxPermessi errati sul socket Unix
Anche se il path del socket è corretto, Nginx potrebbe non avere i permessi necessari per accedervi.
# Messaggio nel log
connect() to unix:/run/php/php8.2-fpm.sock failed (13: Permission denied)
# Verificare i permessi del file
ls -la /run/php/php8.2-fpm.sock
# Esempio di output
srw-rw---- 1 www-data www-data 0 Apr 25 10:00 /run/php/php8.2-fpm.sockverificare quindi che nel file di configurazione del pool PHP-FPM (/etc/php/8.2/fpm/pool.d/www.conf) siano impostati correttamente utente e gruppo
listen.owner = www-data
listen.group = www-data
listen.mode = 0660Se si rende necessario modificare il file di configurazione, riavviare il servizio per rendere attive le modifiche
systemctl restart php8.2-fpmTimeout, PHP-FPM impiega troppo tempo a rispondere
Se uno script PHP esegue operazioni lente (query pesanti, import di file, chiamate a API esterne), può superare il timeout configurato in PHP-FPM o in Nginx, generando un errore 502.
# Messaggio nel log
upstream timed out (110: Connection timed out) while reading response header from upstream
recv() failed (104: Connection reset by peer) while reading response header from upstreamIn questo caso la soluzione può essere quella di aumentare il timeout nel file di configurazione di PHP-FPM e/o nginx. Ma se le richieste impiegano costantemente decine di secondi, il problema reale va cercato nell’applicazione: query non ottimizzate, processi bloccanti, chiamate esterne lente.
# Modifica timeout PHP-FPM - /etc/php/8.2/fpm/pool.d/www.conf
request_terminate_timeout = 120
# Modifica timeout nginx - /etc/nginx/sites-enabled/il-tuo-sito
location ~ \.php$ {
fastcgi_pass unix:/run/php/php8.2-fpm.sock;
fastcgi_read_timeout 120; # deve essere >= di request_terminate_timeout di PHP-FPM
fastcgi_send_timeout 120;
fastcgi_connect_timeout 120;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}Anche in questo caso, dopo le modifiche occorre rendere effettive le modifiche
systemctl restart php8.2-fpm && nginx -t && systemctl reload nginxPHP-FPM ha esaurito i worker (max_children)
PHP-FPM gestisce le richieste tramite un pool di processi worker. Se il numero massimo di worker (pm.max_children) è troppo basso rispetto al traffico ricevuto, le nuove richieste vengono messe in coda o rifiutate, causando l’errore 502.
grep "max_children" /var/log/php8.2-fpm.log
# Messaggio nel log
WARNING: [pool www] server reached pm.max_children setting (5), consider raising itLa soluzione è quindi modificare il numero di processi worker
pm = dynamic
pm.max_children = 20 # aumentare in base alla RAM disponibile
pm.start_servers = 5
pm.min_spare_servers = 3
pm.max_spare_servers = 10Come regola generale, ogni processo PHP-FPM consuma tra 20 e 50 MB di RAM. Su un server con 2 GB di RAM dedicati a PHP-FPM, un valore di pm.max_children = 40 è un punto di partenza ragionevole.
Anche in questo caso, dopo le modifiche occorre rendere effettive le modifiche
systemctl restart php8.2-fpmRisposta upstream troppo grande per i buffer di Nginx
Se il backend restituisce header di risposta molto grandi (ad esempio token JWT lunghi, molti cookie, header personalizzati), nginx può andare in errore per buffer insufficienti.
# Messaggio nel log
upstream sent too big header while reading response header from upstreamDobbiamo quindi aumentare i buffer nella configurazione nginx
server {
...
fastcgi_buffer_size 128k;
fastcgi_buffers 4 256k;
fastcgi_busy_buffers_size 256k;
}Dopo l’eventuale modifica del file di configurazione di nginx, testare e ricaricare
nginx -t && systemctl reload nginxConclusione
Il 502 Bad Gateway su nginx è quasi sempre riconducibile a un problema nel backend a cui nginx inoltra le richieste, non a nginx stesso. Riavviare nginx, come istinto immediato, raramente risolve il problema: il punto di partenza corretto è sempre il log degli errori, che nella maggior parte dei casi indica con precisione la causa.

